Attention Is All You Need
The paper that introduced the Transformer architecture and revolutionized NLP
Complete Illustrated Analysis
The foundational paper behind GPT, BERT, and modern large language models
Introduction: Why Attention Matters
The Sequential Bottleneck
RNNs process tokens one-by-one: token 5 must wait for tokens 1-4 to finish. With 1000 tokens, you need 1000 sequential steps. This is fundamentally incompatible with GPU parallelism.
The Math Problem
Training time scales as O(n) for sequence length n. For long documents, this becomes prohibitive. Modern LLMs process 100K+ tokens—impossible with sequential processing.
Distance-Independent Dependencies
In RNNs, connecting token 1 to token 1000 requires information to flow through 999 intermediate steps—gradients vanish. With attention, token 1 directly attends to token 1000 in a single operation.
Historical Context
Attention was already used in seq2seq models (Bahdanau 2014), but always alongside RNNs. This paper asks: what if attention is the only mechanism?
Background: The Limitations of RNNs and CNNs
Prior Attempts at Parallelism
Others tried CNNs for sequences—convolutions are parallelizable! But CNNs have fixed receptive fields. To connect distant tokens, you need many stacked layers, each adding computational cost.
The Trade-off
- ByteNet/ConvS2S: O(log n) layers needed for distance n
- Transformer: O(1) operations for any distance
Computational Complexity Comparison
| Model | Operations for Distance n |
|---|---|
| RNN | O(n) sequential |
| ConvS2S | O(n) parallel |
| ByteNet | O(log n) parallel |
| Transformer | O(1) parallel |
The Transformer achieves constant-time dependency modeling—a fundamental improvement.
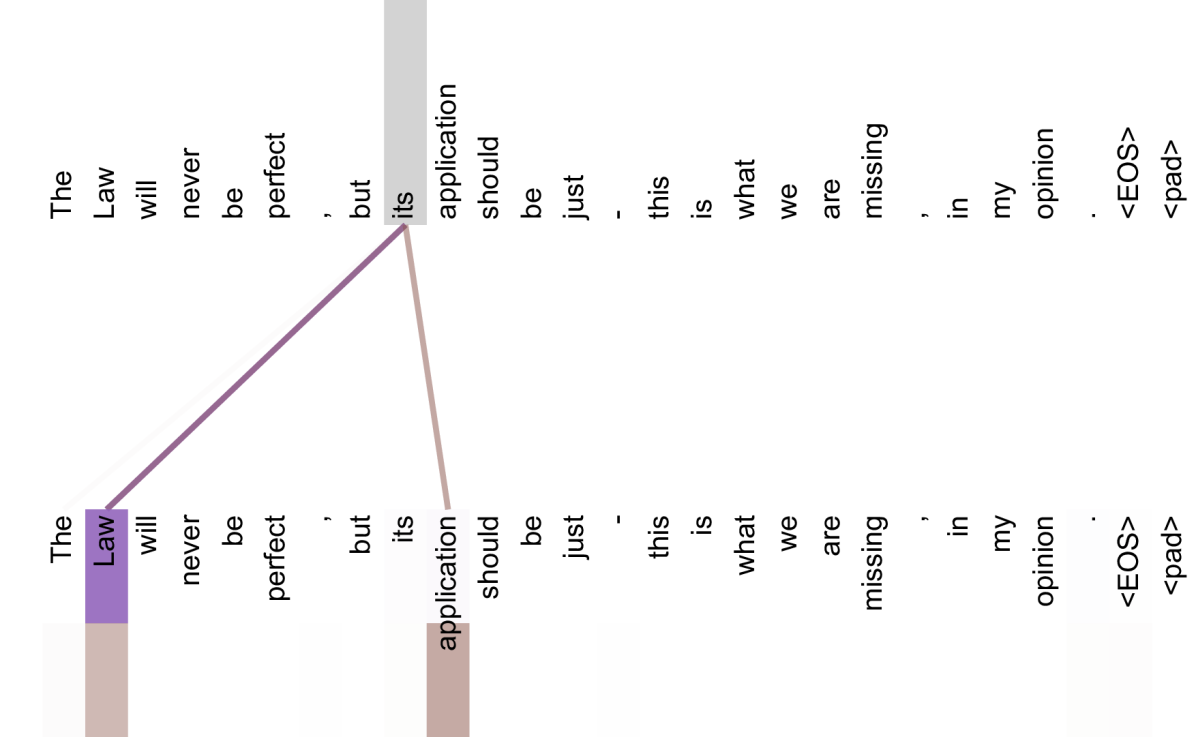
Self-Attention Defined
Traditional attention: decoder attends to encoder. Self-attention: a sequence attends to itself. Every position can directly "look at" every other position in the same sequence.
Why "Self"?
The query, key, and value all come from the same sequence. Position 5 asks "what's relevant to me?" and gets weighted information from positions 1, 2, 3, 4, 6, 7, etc.
Model Architecture Overview

The Big Picture
Despite the revolutionary attention mechanism, the overall structure is familiar: encoder-decoder, just like seq2seq. The innovation is what's inside each component.
Two Components
- Encoder: Processes input sequence → contextual representations
- Decoder: Generates output sequence using encoder output + previous outputs
Input Sequence
↓
┌─────────────────┐
│ ENCODER │ ← 6 identical layers
│ (Self-Attention│ Each: Self-Attention + FFN
│ + Feed-Forward)│
└────────┬────────┘
│
↓ (Keys, Values)
┌─────────────────┐
│ DECODER │ ← 6 identical layers
│ (Masked Self- │ Each: Masked Self-Attention
│ Attention + │ + Encoder-Decoder Attention
│ Cross-Attention│ + FFN
│ + Feed-Forward)│
└────────┬────────┘
↓
Output Sequence
The Two-Phase Process
- Encoding: All input tokens processed in parallel → rich contextual vectors
- Decoding: Output generated autoregressively (one token at a time)
Why Autoregressive Decoding?
Each output token depends on previous outputs. "The cat sat on the ___" → "mat" depends on knowing "cat" and "sat" came before.
Auto-regressive Generation
This is exactly how ChatGPT works! Generate token 1, feed it back, generate token 2, feed both back, generate token 3... The Transformer decoder is the ancestor of GPT.
Training vs. Inference
- Training: Teacher forcing—use ground truth previous tokens
- Inference: Use model's own predictions as previous tokens
The Encoder Stack
Encoder Layer Anatomy
Each of the 6 encoder layers contains exactly two components:
- Multi-Head Self-Attention: Lets each position attend to all positions
- Feed-Forward Network: Applies same MLP to each position independently
Why 6 Layers?
Empirically chosen. More layers = more capacity but more compute. 6 was the sweet spot for translation tasks. Modern LLMs use 32-96+ layers.
Input (512-dim per position)
↓
┌─────────────────────┐
│ Multi-Head │
│ Self-Attention │ ← 8 heads, each 64-dim
└──────────┬──────────┘
↓
Add & Norm ← Residual connection + LayerNorm
↓
┌─────────────────────┐
│ Feed-Forward │
│ Network │ ← 512 → 2048 → 512
└──────────┬──────────┘
↓
Add & Norm ← Residual connection + LayerNorm
↓
Output (512-dim per position)
Residual Connections
From ResNet (2015): add input to output. This creates "skip connections" that help gradients flow during backpropagation through deep networks.
Layer Normalization
Normalizes across the feature dimension (not batch). Stabilizes training by keeping activations in a reasonable range. Critical for training deep Transformers.
The Formula
output = LayerNorm(x + Sublayer(x))
Consistent Dimensionality
Every vector throughout the model is 512-dimensional. This uniformity enables residual connections (you can only add vectors of the same size) and simplifies the architecture.
Scaling Up
The "Big" Transformer uses d_model = 1024. GPT-3 uses 12,288. The architecture scales by increasing this dimension.
The Decoder Stack
Decoder = Encoder + Cross-Attention
The decoder has everything the encoder has, plus a third sub-layer: encoder-decoder attention (cross-attention). This is how the decoder "reads" the encoded input.
Three Sub-layers
- Masked Self-Attention: Attend to previous output positions only
- Encoder-Decoder Attention: Attend to encoder outputs
- Feed-Forward Network: Same as encoder
Input (previous outputs, 512-dim)
↓
┌─────────────────────┐
│ Masked Multi-Head │
│ Self-Attention │ ← Can only see previous positions
└──────────┬──────────┘
↓
Add & Norm
↓
┌─────────────────────┐
│ Multi-Head │
│ Encoder-Decoder │ ← Q from decoder, K/V from encoder
│ Attention │
└──────────┬──────────┘
↓
Add & Norm
↓
┌─────────────────────┐
│ Feed-Forward │
│ Network │
└──────────┬──────────┘
↓
Add & Norm
↓
Output (512-dim)
Causal Masking
The decoder can't "cheat" by looking at future tokens. When predicting position 5, it can only see positions 1-4. This is enforced by setting attention scores to -∞ for future positions (becomes 0 after softmax).
Why This Matters
During training, we process all positions in parallel for efficiency. But logically, each position should only "know" about previous positions—as it would during actual generation.
The Mask
A triangular matrix where position i can attend to positions 1...i but not i+1...n.
Scaled Dot-Product Attention


The Three Vectors
- Query (Q): "What am I looking for?" - the current position's question
- Key (K): "What do I contain?" - each position's identifier
- Value (V): "What information do I have?" - the actual content
Intuition
Like a database: Query searches for matching Keys, then retrieves corresponding Values. High Q·K similarity → more weight on that V.
Step-by-Step Breakdown
- QKT: Dot product gives similarity scores (n×n matrix)
- ÷ √dk: Scale down to prevent extreme values
- softmax: Convert to probabilities (sum to 1)
- × V: Weighted sum of value vectors
Output
Each position gets a weighted combination of all Values, where weights reflect Query-Key similarity.
Why Scale?
With d_k = 64, dot products of random vectors have variance ~64. Large values → softmax saturates → gradients vanish. Dividing by √64 = 8 keeps variance ~1.
The Math
If q, k are random with variance 1, then q·k has variance d_k. Scaling by √d_k normalizes this back to variance 1.
Practical Impact
Without scaling, training becomes unstable. This simple fix enables training deep attention networks.
Multi-Head Attention
Multiple Perspectives
One attention head captures one type of relationship. Multiple heads capture multiple relationship types simultaneously: syntactic, semantic, positional, etc.
The Projection
512-dim vectors are projected to 8 different 64-dim spaces. Each "head" runs attention independently, then results are concatenated back to 512-dim.
where headi = Attention(QWiQ, KWiK, VWiV)
Representation Subspaces
Each head learns to project into a different "subspace" where different relationships are easier to detect. One head might find subject-verb agreement, another might find coreference.
Why Not One Big Head?
A single 512-dim attention would average across all relationship types. Multiple smaller heads can specialize, then combine their findings.
Input: Q, K, V each 512-dim For each of 8 heads: Q × W_Q (512×64) → 64-dim query K × W_K (512×64) → 64-dim key V × W_V (512×64) → 64-dim value Attention output: 64-dim Concat 8 heads: 8 × 64 = 512-dim Final projection: 512 × W_O (512×512) → 512-dim output
The Numbers
- h = 8: Number of attention heads
- d_model = 512: Total model dimension
- d_k = d_v = 64: Dimension per head (512/8)
Compute Efficiency
8 heads × 64-dim = same total compute as 1 head × 512-dim. Multi-head is "free" in terms of computation, but more expressive.
Position-wise Feed-Forward Networks
"Position-wise"
The same MLP is applied independently to each position. No information flows between positions here—that's the attention layer's job. FFN processes each position's 512-dim vector in isolation.
Role of FFN
Attention aggregates information across positions. FFN processes that aggregated information, adding non-linearity and capacity. Think of it as "thinking about what attention gathered."
The Expansion
512 → 2048 → 512. The inner layer is 4× larger! This "bottleneck" structure gives the network capacity to learn complex transformations.
Why ReLU?
ReLU(x) = max(0, x). Simple, effective non-linearity. Modern Transformers often use GELU or SwiGLU instead, but ReLU worked well here.
Parameter Count
W1: 512×2048 = 1M params, W2: 2048×512 = 1M params. FFN contains most of the parameters in each layer!
Positional Encoding
The Position Problem
Attention is permutation-invariant: "cat sat mat" and "mat sat cat" would produce identical attention patterns! Without positional information, the Transformer treats input as a bag of words.
Why RNNs Don't Need This
RNNs process sequentially—position is implicit in the order of processing. Transformers process all positions in parallel, so position must be explicitly encoded.
PE(pos, 2i+1) = cos(pos / 100002i/d_model)
Why Sinusoids?
- Unique encoding: Each position gets a distinct 512-dim vector
- Bounded values: Always between -1 and 1
- Relative positions: PE(pos+k) can be represented as linear function of PE(pos)
- Extrapolation: Works for positions not seen during training
The Geometric Progression
Low dimensions have high-frequency waves (distinguish nearby positions). High dimensions have low-frequency waves (distinguish distant positions).
Relative Position Attention
The model can learn "attend to 3 positions back" as a linear transformation. sin(pos+k) and cos(pos+k) can be expressed using sin(pos), cos(pos), and constants.
Alternative: Learned Positions
The paper also tested learned positional embeddings—nearly identical results. But sinusoidal allows extrapolation to longer sequences than seen during training.
Training Details
The Datasets
- EN-DE: 4.5M sentence pairs (smaller, harder)
- EN-FR: 36M sentence pairs (larger, easier)
WMT Benchmark
Workshop on Machine Translation—the standard benchmark for translation quality. Results are measured in BLEU score (higher = better).
Training Time Revolution
12 hours to train a state-of-the-art translation model! Previous RNN-based models took weeks. The parallelization advantage is massive.
Hardware Context (2017)
8× P100 GPUs was high-end hardware. Today's LLMs train on thousands of GPUs for months, but the efficiency breakthrough started here.
The Warmup Schedule
Learning rate increases linearly for warmup_steps, then decreases proportionally to 1/√step. This prevents early training instability.
Why Warmup?
Early in training, gradients are noisy and can be large. Starting with a small learning rate prevents the model from making huge, incorrect updates before it "settles down."
Base Model: d_model = 512, heads = 8, layers = 6 d_ff = 2048, dropout = 0.1 ~65M parameters Training: 100K steps, 12 hours, 8× P100 Big Model: d_model = 1024, heads = 16, layers = 6 d_ff = 4096, dropout = 0.3 ~213M parameters Training: 300K steps, 3.5 days, 8× P100
Regularization Techniques
- Dropout: Randomly zero 10% of values → prevents overfitting
- Label Smoothing: Instead of hard targets (0 or 1), use soft targets (0.1 or 0.9) → improves generalization
Label Smoothing Effect
Hurts perplexity (model is less confident) but improves BLEU (actual translation quality). The model learns to be appropriately uncertain.
Results and Experiments
Breaking Records
+2.0 BLEU is a huge improvement in translation quality. The Transformer didn't just match RNN ensembles—it crushed single models that took much longer to train.
Quality + Speed
Previous SOTA required ensembling multiple slow models. Transformer achieves better results with a single model in a fraction of the training time.
| Model | EN-DE BLEU | EN-FR BLEU | Training Cost |
|---|---|---|---|
| Previous SOTA (ensemble) | 26.4 | 41.0 | High |
| Transformer (base) | 27.3 | 38.1 | 12 hours |
| Transformer (big) | 28.4 | 41.8 | 3.5 days |
Efficiency Breakthrough
Same quality, 4× less training cost. This is the key result: Transformers aren't just better, they're dramatically more efficient to train.
The Implication
If you can train 4× faster, you can iterate 4× more on architecture/hyperparameters. This accelerates research. The modern LLM explosion was enabled by this efficiency.
Ablation Studies
The paper systematically tested: What happens if we change the number of heads? Reduce dimensions? Remove components? This tells us what actually matters.
Key Findings
- Single-head attention hurts quality significantly
- Reducing d_k hurts quality (attention needs capacity)
- Bigger models = better, but with diminishing returns
- Dropout is essential for regularization
Conclusion and Historical Impact




The Summary
The paper's contribution is architectural: prove that attention alone is sufficient for sequence transduction. No recurrence needed. This was controversial at the time—RNNs were deeply entrenched.
What "Attention Is All You Need" Means
The title is a bold claim: you don't need LSTMs, GRUs, or any recurrent structure. Attention mechanisms, when properly designed, can handle everything.
Prophetic Words
This understated conclusion predicted everything that followed. Transformers now dominate:
- Language: GPT, BERT, T5, LLaMA, Claude
- Vision: ViT, CLIP, DALL-E
- Audio: Whisper, AudioLM
- Multimodal: GPT-4V, Gemini
- Protein: AlphaFold2
Historical Impact (2017-2025)
| Year | Milestone |
|---|---|
| 2017 | Transformer paper published |
| 2018 | BERT revolutionizes NLP understanding |
| 2018 | GPT-1 shows generative potential |
| 2019 | GPT-2 demonstrates emergent abilities |
| 2020 | GPT-3 (175B params) stuns the world |
| 2022 | ChatGPT launches AI mainstream adoption |
| 2023 | GPT-4, Claude 2 show reasoning capabilities |
| 2024 | Multimodal AI becomes standard |
Technical Specifications
Complete architecture parameters and configurations
The Revolutionary Claim
This single sentence upends decades of sequence modeling. Before 2017, the dominant paradigm was: RNNs for sequences, CNNs for images. The authors boldly claim attention alone is sufficient—no recurrence, no convolutions.
Why This Matters